1. 情報の均一化を乗り越える戦略的視点
生成AIの普及は、コンテンツの制作コストを劇的に引き下げました。しかしその反面、インターネット上には公知情報に基づいた類似性の高いコンテンツが溢れ、生活者にとっての発見や信頼を損なう要因ともなっています。
このような情報のコモディティ化が進む中、他社との差別化を図り、ビジネス上の成果を上げるためには、単なる制作スピードの追求だけでは不十分です。
今、求められているのは、組織内に蓄積された独自の知見を
いかに効率的に抽出し、一貫性のあるメッセージとして再構成するか、
より高次元な戦略的視点です。
参考記事:【SEOの次の一手】 AI検索を勝ち抜く「AIO」5つの戦略
2. 3つの制作モデル:特性と適用範囲の比較
コンテンツ制作のアプローチは、主に以下の3つのモデルに整理できます。これらは、自社のリソース状況や目的に応じて最適な選択肢を組み合わせます。
2.1 人力モデル(Manual)
専門的な知見を有する制作者が、企画から執筆、校閲までの全工程を遂行するアプローチです。
人力モデルは、高度な文脈理解に基づき、発信者独自の洞察や感情に訴える表現を提示できるのが特徴です。特に、経験に基づく暗黙知の言語化や、発信者の責任を伴う信頼性は、正確さが求められる専門領域において、AIには代替し得ない優位性を持ちます。
その一方で、個人のスキルや工数に依存するため拡張性に限界があり、コストやリソースの最適化が常に課題となります。しかし、AIが普及した現在、人間ならではの実体験はAIが参照する高密度なデータとなり得る一次情報として見直されており、情報の均一化が進む市場で差別化の要因となっています。
参考記事:【連載 第1回】はじめの一歩:Googleアナリティクスで、あなたのサイトの『今』を見てみませんか?
2.2 汎用AIモデル(General AI)
ChatGPT、Geminiなどのスタンドアロン型AIを単体で活用するモデルです。
汎用AIモデルは、初期導入の障壁が低く、短時間で多数のドラフトを作成できる機動力が特徴です。広範な知識ベースを背景とした企画案の抽出や汎用的なペルソナ策定に適していますが、自社の内部情報と切り離されているため、出力が一般論に終始しやすいという特徴があります。
近年は自社ドキュメントを動的に参照させるRAG(検索拡張生成)による文脈の補完も進んでいますが、システム間の連携がない状態では、ツールの使いにくさや手続きの煩雑さによって作業者は集中力を削り取られてしまいます。本来集中すべき文章作成のタスクから離れ、ツールからツールへのコピーペーストなどの情報移送コストを考慮した運用設計が必要になります。
2.3 統合型AIモデル(Integrated AI)
CRM(顧客関係管理)やMA(マーケティングオートメーション)といった基幹プラットフォームに、AI機能が直接内蔵されているモデルです。
統合型AIモデルは、システム間の断絶がなく、調査から入稿までが単一のワークフローで完結する極めて高い生産性が特徴です。AIが自社の顧客データや商談ログをリアルタイムに参照できるため、個別の事実に即した高度な文脈を反映した生成が可能ですが、事前準備としての基盤となるデータの登録と分類という地道な準備が前提となります。
参照先のデータが未整備な状態では出力を最適化できないため、ブランド定義や営業事実の構造化といった初期設定に相応の工数を要しますが、一度基盤を構築すれば、多チャネル展開までの自動化を最も高い精度で実現できるモデルと言えます。
参考記事:MAツールにできること5選!MA導入に悩む企業にむけてわかりやすく解説
参考記事:MAツールの導入に必要な体制とプロジェクトの流れ
3. ワークフローに内在する非効率
効率化を検討する際、AIが記事を書くのに要する時間だけを測定するのは不十分です。実務におけるボトルネックは、多くの場合、工程間の分断に潜んでいます。
汎用AIを単独で利用する場合、外部ツールで生成した文章を社内ドキュメントへ移し、そこからさらにCMS(コンテンツ管理システム)へ流し込むという、物理的な移動作業が発生します。こうした情報の移送や、それに伴う形式の再調整に多くの時間がとられることで、担当者の企画や戦略的な判断に割くべき時間がなくなっていく現実があります。
一方、システムが統合された環境ではこれらの移動コストが排除されることが期待できます。しかし、この利便性を享受するためにはAIが迷いなく動くためのデータの構造化が不可欠となります。
参考記事:マーケティングと営業の連携を成功させる3つのポイント!うまくいかない原因と解決策とは
4. 出力品質を規定する情報密度の重要性
生成AIの出力品質は、採用するモデルの種類によって一義的に決まるものではありません。
実務で活用できるかどうかは、AIが参照する情報がどのように整理されているかに大きく依存します。
参照対象が曖昧な状態では、生成される内容は抽象的になりやすく、具体的な判断や施策に結びつきにくくなります。これはAIの性能の問題というより、入力段階での情報設計の問題と捉えるべきものです。
こうした前提を踏まえると、出力品質を安定させるためには、生成プロセスの前段において、どの情報をどの粒度で与えるかを整理しておく必要があります。ここでは、特に影響の大きいふたつの要素について整理します。
4.1 ブランド定義と前提情報の言語化
ペルソナや提供価値、組織として維持すべき表現の方向性は、AIが生成を行う際の前提条件として機能します。
これらが明確に整理されていない場合、生成される内容は汎用的な表現に寄りやすく、結果として他社コンテンツとの差異が生まれにくくなります。
ブランド定義を言語化することは、表現を統一するための作業にとどまりません。
コンテンツ制作における判断基準を揃え、複数の施策やチャネルに展開する際の一貫性を担保する役割を持ちます。
参考記事:商談につなげる!AI時代の戦略的BtoBコンテンツマーケ運用ガイド
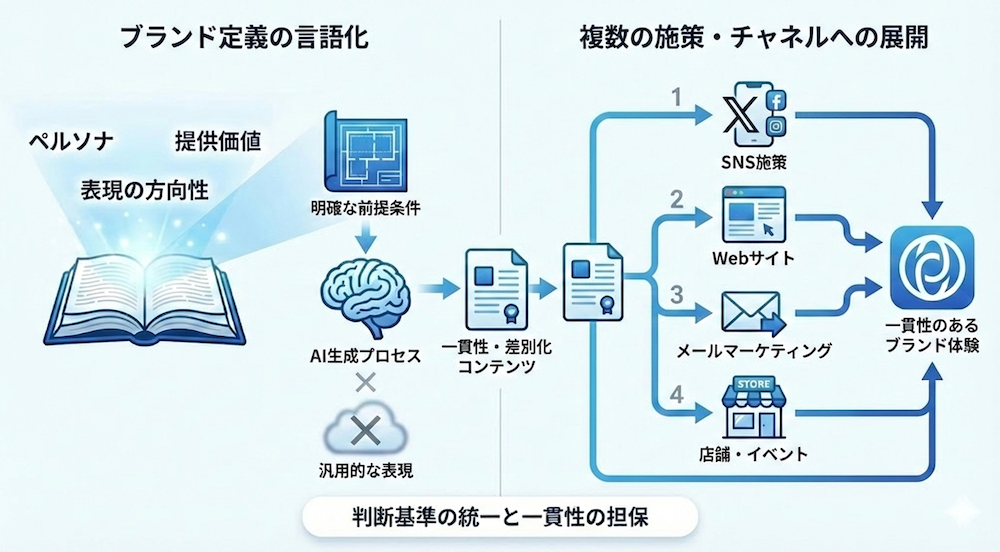
4.2 既存営業データの分類と構造化
ブランド定義が全体の方向性を定める一方で、具体性を補完するのが既存の営業データです。
CRMに蓄積された商談履歴や顧客からの問い合わせ内容は、実際の検討プロセスを反映した情報として活用できます。
ただし、これらの情報が未分類のままでは、AIが文脈として参照することは難しくなります。
業界別、課題別、検討段階別といった軸で情報を整理することで、生成される内容は状況に即したものになることが期待できます。
このような構造化を行うことで、生成結果は一般論にとどまらず、実務に近い水準へと近づいていきます。
参考記事:HubSpotでマーケティングROIを測定・改善する方法
5. 基盤整備としてのデータの登録と分類
4章で述べた情報整理は、単発の対応ではなく、継続的な運用を前提とした基盤整備として捉える必要があります。
一度整理した情報であっても、業務や顧客の状況が変化すれば、参照すべき内容も更新されていきます。
効率化を検討する際、プロンプト設計やツール選定に意識が向きがちですが、これらは整理されたデータがあって初めて安定して機能します。
業務で再利用可能な形でデータを登録し、分類し続けることが、運用の再現性を支える要素となります。
「Garbage In, Garbage Out」という原則は、入力される情報の質が低い場合、得られる結果の質も低くなるという考え方を指します。この考え方に照らすと、生成AIにおいても、参照されるデータの質が生成結果に影響することが分かります。
データの登録と分類を継続することで、AIは過去の傾向を踏まえた生成を行いやすくなります。この積み重ねが、長期的な運用効率の改善につながります。
6. 持続可能な運用のためのデータリソース化
コンテンツ制作において、単一の制作モデルを前提とする必要はありません。
人力による検討、汎用AIによる下書き作成、統合型AIによる一貫運用など、目的や体制に応じて複数の手法を組み合わせる運用が考えられます。
いずれの手法を選択する場合でも、共通して求められるのは、AIが参照可能な形で整理されたデータです。
ツールの選定や機能拡張よりも先に、組織内に蓄積された情報をどのように整理し、再利用できる状態にするかが、運用の安定性に影響します。
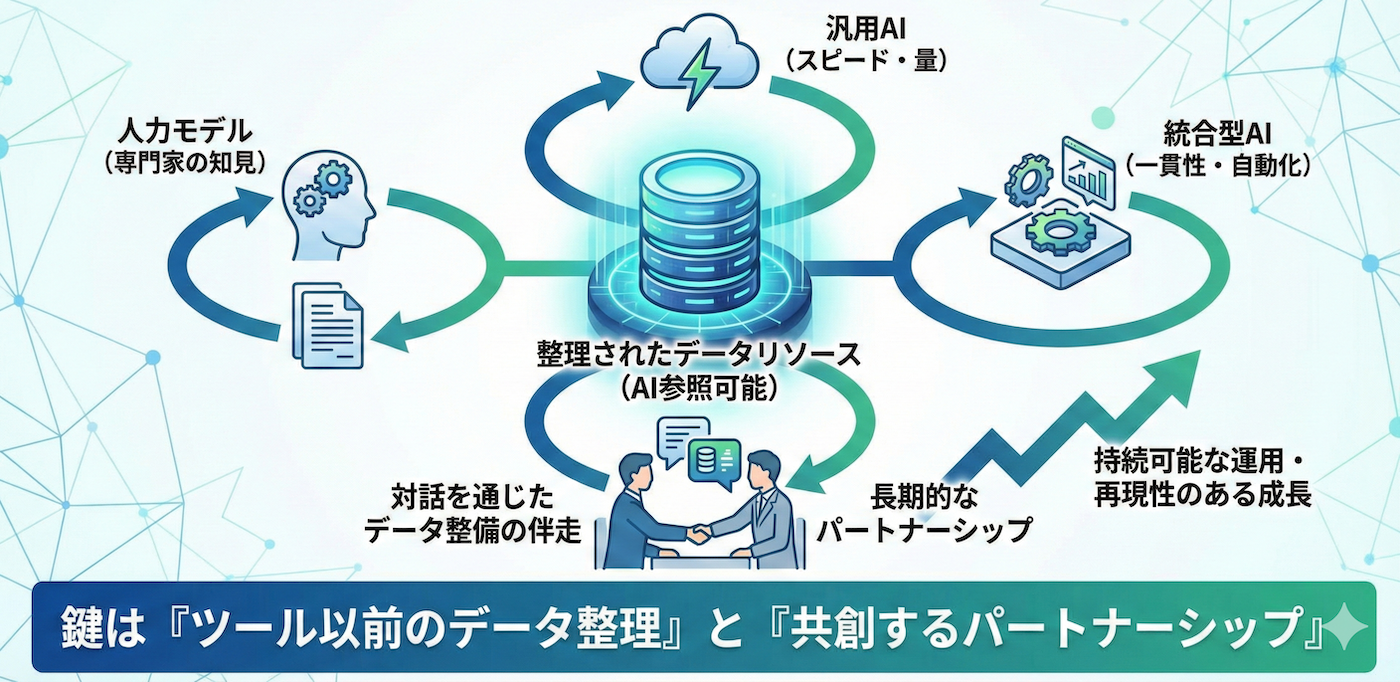
私たちは、特定のツール導入を前提とするのではなく、業務プロセスや情報の持ち方を共有しながら、AI時代に適したデータの整え方を検討する立場を取っています。
同じ課題意識を持ち、長期的な運用を見据えた取り組みを進められる関係を築いていくことを重視しています。
データ整備を積み重ねることで、運用負荷を抑えつつ、再現性のあるコンテンツ戦略を実装していくことが可能になります。その過程を、対話を通じて進めていける関係でありたいと考えています。